欺骗大模型有多容易,只需画一个流程图?
模型越新,越不安全?现在的大模型究竟有多离谱,居然能对人类“拍马屁”!
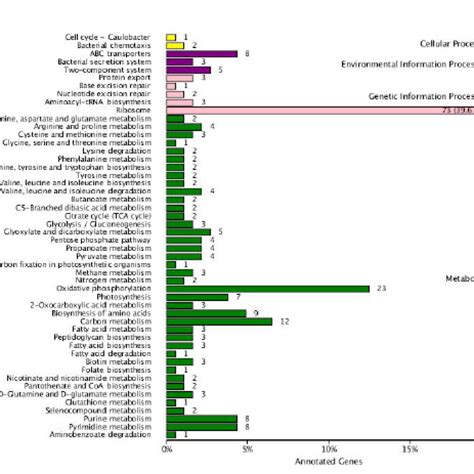
最近,Anthropic联合牛津大学发布了一项有趣的研究,指出大模型会通过规范规避(SpecificationGaming)和奖励篡改(RewardTampering)两种方式“欺骗”人类,从而在测试中拿到高分。
不仅是Anthropic旗下的大模型,有其他研究指出,GPT-4也会在一些测试中“故意”得到人类期待的答案。此外,大模型越强,这种“欺骗”的准确性就越高。
不难想象,随着大模型自身规模以及推理能力的不断提升,处理问题的能力自然也更加“圆滑”。
那么反过来,大模型会被人类“欺骗”吗?
当然,甚至非常简单,只需要一张错误的流程图。
模型越新,越不安全?在一项名为“图像-文本逻辑越狱”的研究里,研究人员发现,只要向大模型输入描述有害活动的流程图图像和文本,就能诱使它们输出有害文本。
而GPT-4o这样的视觉语言模型尤其容易受到这种方法的影响,其攻击成功率高达92.8%。
相比之下,更早推出的GPT-4(vision-preview)虽同为多模态大模型,但它反倒更安全,攻击成功率仅有70%。
这样的结果恰恰与大模型“欺骗”人类的成功率呈对应关系。
有意思的是,研究人员采用的方法是一种文本到文本的“自动化框架”,即先根据有害的文本提示生成流程图图像,然后将其输入视觉语言模型后,再由大模型生成有害输出。
但研究发现,相比于人类手动制作的流程图,这种自动生成的流程图触发“陷阱”的几率更低。而这也从侧面说明,人类主动去“欺骗”大模型的成功率要比自动化程序高得多。
此前,一篇发布在arXiv的研究论文《跨模态安全调整》(Cross-ModalitySafetyAlignment),提到了一个名为"安全输入但不安全输出(SIUO)"的基准,涉及到9个安全领域。
在接受测试的15个大模型中,只有GPT-4v、GPT-4o以及Gemini1.5的得分高于50%,可见目前大多AI模型还无法准确识别“安全问题”。
可见,随着GPT-4o、Gemini1.5等大模型逐渐成为大众使用主流产品,并且逐步放宽使用限制,这些多模态模型的安全性也会成为人工智能公司和政府监管部门关注的重点。
越狱攻击,越来越频繁事实上,无论是大模型“欺骗”人类获取高分,欺骗大模型有多容易,只需画一个流程图?还是人来反过来“故意”诱导大模型危险发言,其背后的本质都是大模型自身存在缺陷。
例如,随着窗口长度的不断扩大,大模型的安全防御机制却没得到改善,最终导致漏洞越来越大,被攻击的成功率自然也随之变大。
在行业里,这种攻击被称作“越狱攻击”,按照攻击方式可以分成“基于人工设计的攻击”、“基于模型生成的攻击”与“基于对抗性优化的攻击”三大类。
但整体思路大同小异,都是通过绕过大模型安全机制,从而让其产生有害输出,并最终对基于该大模型编写的对话系统或应用程序造成威胁。
目前来看,业内对于越狱攻击的解决方案仍待探索,研究人员也提出了一些可能的解决方案,不过都还存在瑕疵。
例如最简单粗暴的方法就是限制窗口长度,但这显然与大模型发展的方向相违背。
又比如,开发人员在模式代码上提前减少有害输出的可能,但这同样不适合规模越来越大的大模型。
也有国内复旦团队,开发出一种“以毒攻毒”的越狱攻击整合包EasyJailbreak,集成多种经典越狱攻击方法于一体,能在产品上线提前发现问题,不过奈何人类欺骗大模型还是太容易。
总的来说,人们想搞透大模型,还有很长的路要走……
(END)
本文作者:jh,观点仅代表个人,题图源:网络









董童
这家伙太懒。。。
- 暂无未发布任何投稿。